|
The last 18 months or so have been one of the most exciting periods for growth of AI. It’s interesting that while the field of AI has been around for decades and maturing rapidly on its own, the introduction of Large Language Models and Generative AI has created a massive amount of adoption and interest across all communities. Perhaps one of the easiest explanations for this is the nature of the output from these AI models. They cater to one of our social needs – the need for communication / use of language to exchange information.
Unlike traditional AI models, these textual or conversational outputs from Generative AI models are not mathematical in nature or require any additional explanation. Instead, they can deliver information to us in a form that we easily understand every day. More importantly, we can “instruct” these models to provide us with outputs in a manner that we can comprehend easily, again, without the need for sophisticated programming languages or the mathematical basis required previously. In my introductory blog post, I outline some of the characteristics of Large Language Models and why they are well-suited to drive academic or business outcomes. I also highlighted the true nature of such models, the black box problem, and emergent behavior, all of which essentially boil down to this: While the application of LLMs can have a profound impact in helping societies, how LLMs work internally remains an important area of research. As more such Generative AI models become commonplace, researchers are making progress in trying to understand “how” these Large Language Models interpret information and whether their outputs can be trusted. In one such recent such ground-breaking development, researchers at OpenAI attempted to decompose the internal representation of GPT-4 into millions of interpretable patterns. According to the researchers: Unlike with most human creations, we don’t really understand the inner workings of neural networks. For example, engineers can directly design, assess, and fix cars based on the specifications of their components, ensuring safety and performance. However, neural networks are not designed directly; we instead design the algorithms that train them. The resulting networks are not well understood and cannot be easily decomposed into identifiable parts. This means we cannot reason about AI safety the same way we reason about something like car safety. In the next section, I will attempt to explain autoencoders, a type of artificial neural network, that can potentially provide some initial insights into the inner workings of large language models such as GPTs (Generative Pre-trained Transformers). Autoencoders were used by the researchers at OpenAI to identify activation patterns in the neurons and correlate them to identifiable concepts that were understandable by humans. Autoencoders Autoencoders can help understand the inner workings of a neural network by providing insights into how data is represented and processed within the network. In simple terms, it compresses input data into a smaller feature set and then attempts to reconstruct the original input from this compressed set of features. IBM has an excellent article on autoencoders for those who want more details. Here’s how autoencoders can be useful in understanding models like GPT-4: Dimensionality Reduction and Visualization:
Implementation & Results For those of you interested in code and practical implementation of autoencoders, I recommend starting with some basics. Use keras and tensorflow to perform these steps:

Once you understand how autoencoders work, we can look at how to apply this to better comprehend the inner workings of LLMs.
Applications of Autoencoders to understanding LLMs. As you are reading through this next section, please refer to the SAE Viewer from OpenAI to understand how activations occur for different concepts for GPT-4 or GPT-2. In the context of large language models (LLMs), autoencoders can be trained on the activations of the LLM. This helps to identify and visualize the features that the LLM uses to understand and generate language. To best understand this, it is worth looking at an example with some data that we can all relate to.
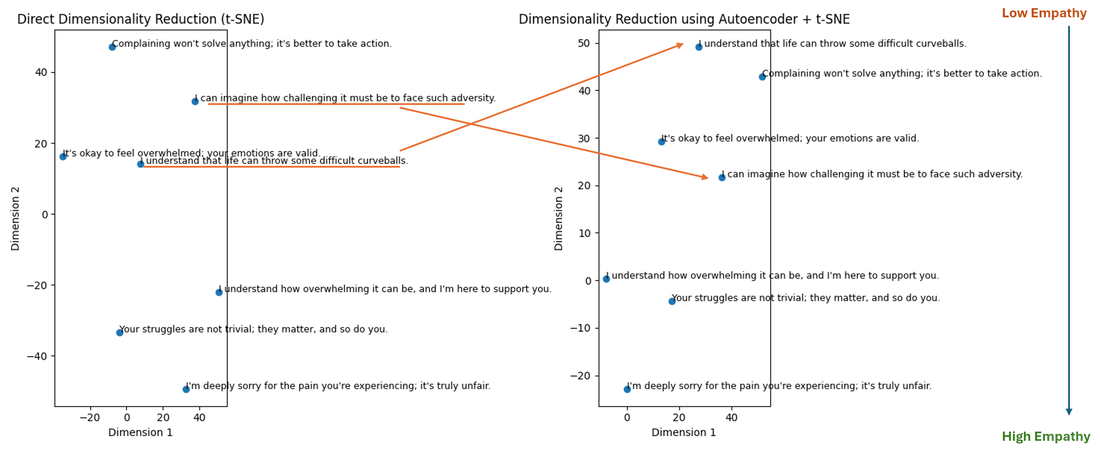
As you can see, some of the nuance in how close each sentence is in “empathy” to the other is lost in the direct embedding, but preserved with the autoencoder, allowing us to better understand how the LLM “embeds” this data and makes meaning out of it. For the image on the right, read each sentence from top to bottom, and check if you agree with the level of empathy that can be ascribed to each sentence (knowing of course that this can be subjective). Without performing a scientific analysis, I’d say that we can almost see a correlation between the embedding and the level of empathy (as indicated by the arrow on the right).
This is by no means, a comprehensive sample, and the nature of the output, its interpretation, and eventual utilization depend on various factors, including the chosen embedding model, but at least, this begins to give us some idea as to how an LLM may interpret inputs and outputs. The potential to build on this ability and its applications are what we are focused on at Relativ, my new startup, where we deploy customized AI models for personalized conversational analytics at scale. So, to recap, let’s do a quick summary of how autoencoders can be used to describe the inner workings of neural networks. Autoencoders can help by:
Implications for Transparency, Understandability, Trust & Safety One of the biggest drawbacks with the black box nature of LLMs is whether we can trust their outputs. This is particularly true if the Generative AI models are used in any capacity to provide advice, coaching, tutoring, or information that is necessary for learning and development. One such limitation of LLMs that is inherently present is termed as hallucination, which you can read more about in this article. While there are ways to mitigate this, the underlying question of why LLMs hallucinate, and how these large neural networks remain of interest. Unless we can “trust” the information provided by the AI model, which in turn translates to reliability and repeatability, and know that the information can be “safely” consumed, serious applications of AI to help us in daily life may be counterproductive. Another aspect of this is the question of “transparency” and “understandability” of AI models. This is a related aspect that governs the nature of the data used to train the neural network. The ways in which a neural network may learn information and fire activations may be largely dependent on the input data. Without transparent information on how the AI model is producing its outputs, and what data was used to train the model, it is difficult to truly “understand” what the output from the model means. This is why researchers are so keen on understanding the inner workings of neural networks. Autoencoders are one such powerful tool available to us, and researchers are already starting to make progress towards this goal. At Relativ, we continue to focus on these aspects as the cornerstones of all our customized AI models. We know what data goes in, and we define what data comes out, in collaboration with our partners and clients. If you’d like to learn more about how we can help you integrate customized AI models to support your organization’s academic or business goals, please reach out. We’re always looking for people who care deeply about the positive impact of AI on our societies while keeping privacy, transparency, trust, and safety as our most important guiding rails. I hope you enjoyed reading this as much as I enjoyed writing it!
0 Comments
|
AboutArjun is an entrepreneur, technologist, and researcher, working at the intersection of machine learning, robotics, human psychology, and learning sciences. His passion lies in combining technological advancements in remote-operation, virtual reality, and control system theory to create high-impact products and applications. Archives
April 2025
Categories
All
|
 RSS Feed
RSS Feed